

Starting a project with big data: where to begin?
Being handed the keys to a new dataset is exciting (even if it is just the exchange of a password and login information, and whitelisting an IP address). Perusing documentation, learning variable names and the database schema, and other preparatory work doesn’t compare to seeing the results of your first query show up on screen. In this post I’ll describe some of the initial steps I took to become familiar with the Worldreader dataset, to give you insight into how a data analyst approaches a new big data project.
Geolocation and Mobile Data
In the past decade there has been an explosion of digital applications that collect and make use of the geographic location of users (Kitchin, Lauriault, and Wilson 2017). These apps are often used on mobile devices capable of identifying a user’s location with a high degree of accuracy, enabling the delivery of highly customized services based on that location. As a result, location-based services (LBS’s) are now used for everything from navigation and provision of government services (e.g., Mattern 2017) to the tracking of global pandemics (Sparke 2011) and the detection of earthquakes (e.g. Young et al. 2013). Although research based on these datasets remains new, it is already clear that spatial data are capable of unlocking many new forms of powerful analysis.
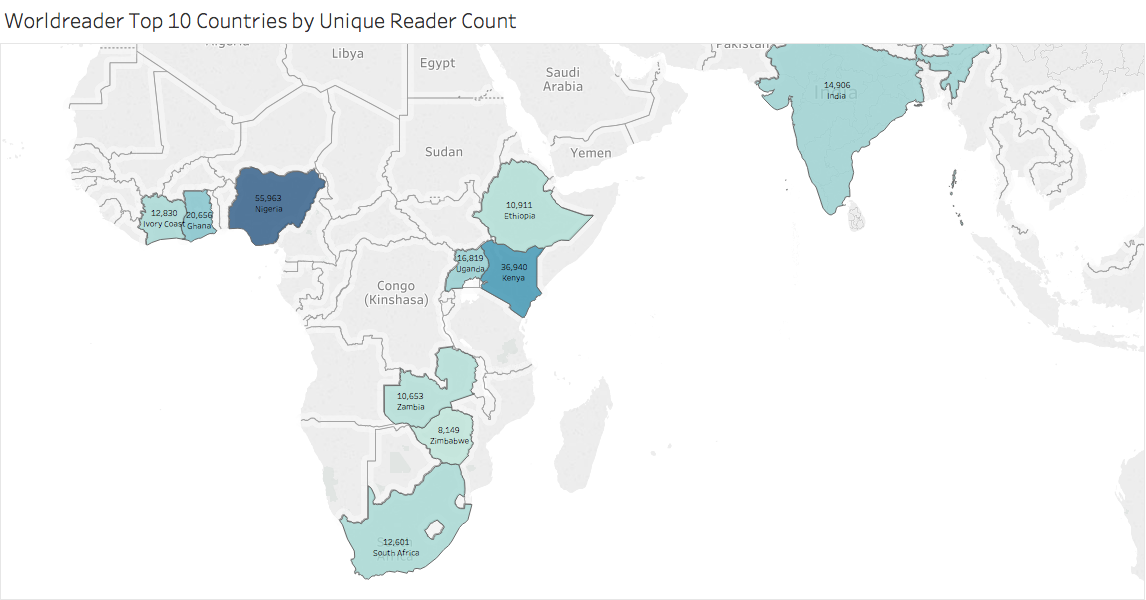
Exploratory Data Analysis
In the article, “Creating a Data Analysis Plan: What to Consider When Choosing Statistics for a Study,” Scot Simpson states that “the first step in a data analysis plan is to describe the data collected in the study” (2015 p. 312). In a previous blog post, Lucas outlined the data variables in our dataset. With those variables in mind, I will present some descriptive statistics of our overall data, and two smaller segments of the overall data.
