

User Preferences: Part 2, Queries
Our last post examined user genre preferences within Worldreader’s Lifelong Reading Program. As we described in that post, those analyses provided valuable insights into the current Worldreader material that users are accessing, but a second source of information can provide even finer-grained details on what users want to be accessing. This comes in the form of user queries, which will be the focus of this post.
User Preferences: Part 1, Genre
In a previous post, we examined genre progression within registered users from Nigeria. In that analysis, we found that love was one of the most popular categories, and tended to retain users relative to other categories. However, the analysis left us with a lot of additional, and important, questions about the genre preferences of Worldreader users.
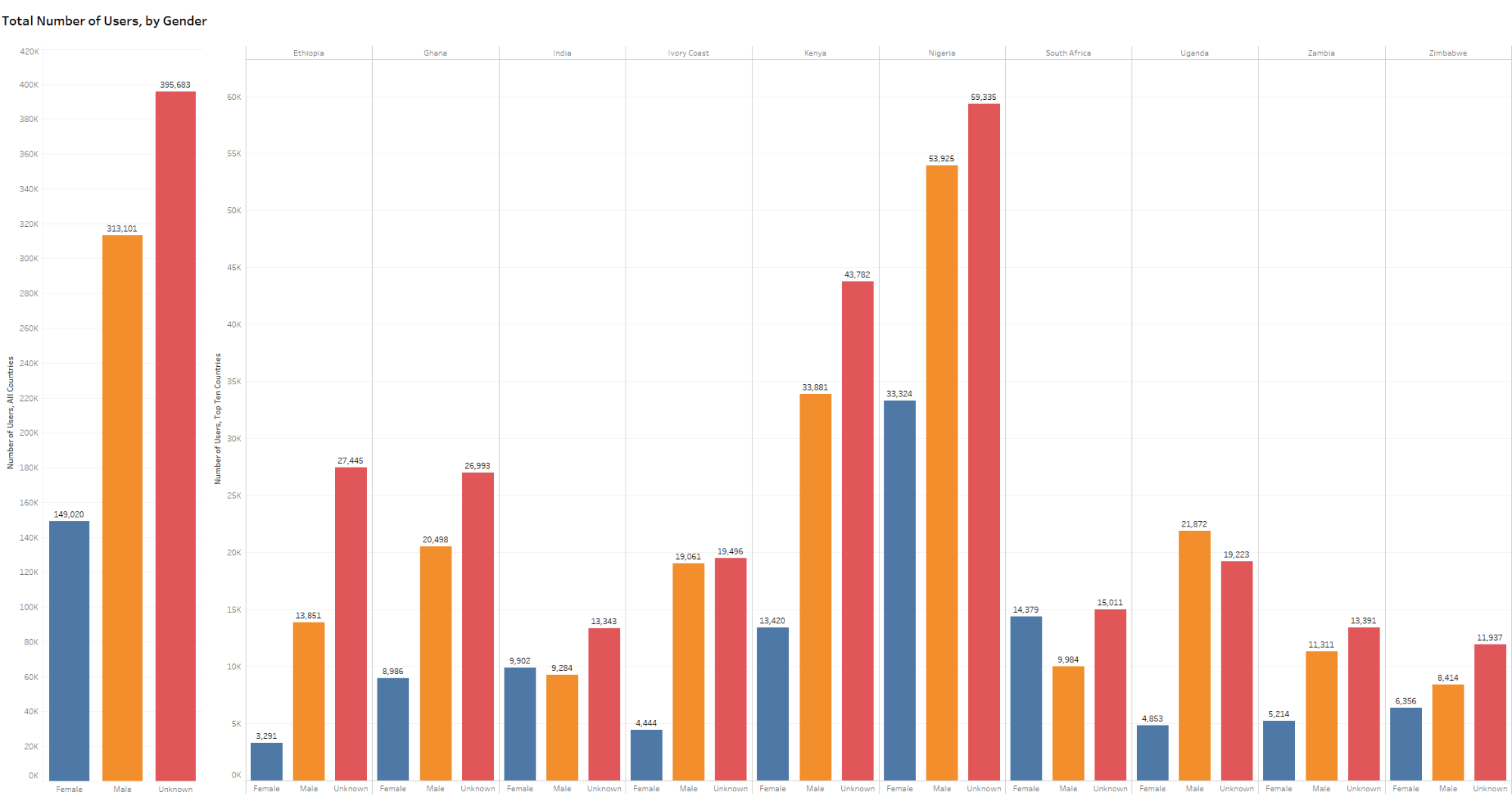
Gender, Access, and Reading Behavior
This project was largely inspired by a 2014 collaboration between UNESCO and Worldreader, which sought to develop “insights into how mobile technology can be leveraged to better facilitate reading in countries where literacy rates are low.” (UNESCO 2014, 9) The problem of increasing literacy is particularly tricky in many of these contexts, since educational opportunities – including those offered through mobile devices – are often not equally accessible by all segments of the population.
