Posted January 12, 2018
By Jason Young
The last week of October marked the 10th annual celebration of Open Access Week, an event designed to “help inspire wider participation in helping to make Open Access a new norm in scholarship and research.” The Open Access and Open Data movements are becoming increasingly visible, both within research communities and with the general public. A recent study by Figshare, an organization that facilitates open sharing of academic research, found that 82% of surveyed researchers have become more aware of open data sets in the last year. 74% of their respondents also indicated that they are curating their data for sharing. Beyond academia, openness has become increasingly popularized in areas ranging from technology to governance. As of today, for instance, 75 countries and 15 subnational governments have joined the Open Data Partnership, an organization dedicated to making governments more open and accountable. Mirroring other arguments for openness, proponents of the organization argue that open data have the potential to “promote transparency, empower citizens, and harness new technologies to strengthen governance.” Both Worldreader and TASCHA have long had an interest in open data, and we are dedicated to making this research project as open as possible. In this blog post we describe some of the emerging concepts related to openness, and then explore ongoing debates over the benefits and drawbacks of open approaches. The end of this post then ties these debate to our own research practices and ethics.
Open Data, Open Access, Open Content, Open Science, Open Source… given the proliferation of different types of openness, it can be difficult to keep track of all of the terms! In this section we review the history of open movements, with a focus on open access and open data as they relate to research projects like the Mobile Reading Data Exchange.
The idea that information should be open is far from new – Sweden, for instance, passed legislation governing open access to government documents as far back as 1766 (Lauriault and Francoli 2017). And, on the academic side of the equation, the 1940s and 1950s saw a number of researchers and organizations – ranging from sociologist Robert King Merton and physicist Leo Szilard to the radical collective Letterist International (LI) – pushing forward the idea that knowledge should be free for all to access and use. Despite this long history, the movement toward openness has gained the most speed in the last few decades, with the emergence of digital and networking technologies (like the Internet).
One of the earliest examples of an open, digital project was Project Gutenberg. This project, which began in 1971, was a volunteer effort to digitize books for free public consumption. This can be characterized as an Open Access (OA) project because the focus was on increasing free access to digital publications. In the context of government, OA projects increase access to government documents and reports. In the context of academia, they increase access to publications resulting from research, such as journal articles or books.
OA advocates argue that these publications should not be restricted to organizations that can afford to pay (often exorbitant) subscription fees. Opening up access not only democratizes knowledge, they argue, but also has direct benefits for the authors of the publications. By increasing access to the publications, OA platforms also increase the uptake, usage, and, ultimately, impact of scholarly research. The OA movement really took off in the 1990s, with the rapid expansion of open access journals and archives. Following the success of some of these platforms, many organizations began releasing statements of support for OA in the early 2000s. These included the Budapest Open Access Initiative (2002), the Bethesda Statement on Open Access Publishing (2003), and the Lyon Declaration on Access to Information and Development (2014), among others. In 2001 Creative Commons was founded as an organization dedicated to sharing knowledge.
The Open Data movement is an attempt to expand OA to include access to the underlying data that support research. One of the earliest definitions of Open Data came from the UK-based Open Knowledge Foundation. Drawing from prior work on open source software, their 2005 Open Definition identified three key principles behind that define data openness:
The definition also stresses that the data must be open from both a legal and a technical standpoint. In other words, there should be neither laws nor technical barriers that make it unreasonably difficult to access and use the data.
Since 2005 many other organizations have drafted their own definitions and statements on Open Data. In the United States, for instance, many sources identify 2007 as a landmark year for Open Data. In December 2007 thirty thinkers and data activists came together in Sebastopol, California to draft open data principles. Their 8 principles remain widely cited today, and include the following:
Many of the participants at this meeting were also inspired by the open source software movement, which stressed the concepts of openness, participation, and collaboration. They sought to provide a framework for sharing and using data that would preserve those data as a common good for all. Since this meeting the open data movement has gained a lot of popularity, but many debates still remain. We explore some of these in the next section.
Proponents of openness cite a wide range of benefits, ranging from the mundane to the revolutionary. As mentioned above, OA can increase the uptake, use, and impact of academic publications. OA therefore offers value for both the writers and readers of those publications. Going a step farther, Open Data can facilitate the replication of studies, allow broader research agendas to coalesce around datasets, make expensive or difficult-to-collect data more accessible, and even inspire new research partnerships. Outside of the research world, proponents of open government have argued that open data can increase government efficiency, reduce costs related to individual data requests, and even increase data quality. In a 2013 study the McKinsey Global Institute estimated that open data could generate more than $3 trillion a year in additional value for private industry. Others go even farther, arguing that digital technologies have the potential to shift the world away from unjust and proprietary business models, and therefore to “empower those who are least well off” (Benkler 2006: 16). Moves toward openness are often framed ideologically around principles of democratic empowerment, transparency and accountability, and public participation (Lauriault 2017; Young and Gilmore 2014). From this view open data offer not only pragmatic benefits, but also a chance at a more ethical world.
However, openness does not always live up to these lofty goals. As geographer Tracey Lauriault (2017) points out, “open data as a movement has done much good, but it has not yet met its ideal state where evidence-informed and participatory policy-making is the norm” (100). More troublingly, in some instances OA and Open Data frameworks can produce problems, particularly if information is opened up into social and political contexts that are structured by other types of inequalities. For example, researchers working with indigenous communities have often highlighted the potential dangers of sharing indigenous knowledge in ways that can lead those communities to experience increased exploitation. In a previous project that one of our project members worked on, for instance, indigenous communities did not want their knowledge of local environmental resources to become too open. Because they had few legal or economic protections, they feared that their knowledge would easily be exploited by biopharmaceutical companies, loggers, and poachers if it was shared broadly. Indigenous research is littered with unfortunate examples of how local knowledge can be exploited by government agencies and private corporations, producing new forms of data colonialism.
Of course, indigenous communities are not the only populations at risk of new forms of data exploitation – openness is quickly generating novel economies with their own winners and losers. New stories emerge weekly about new ways that privacy has been eroded and personal data have been marketized within novel service models. More closely related to this project, publishers have criticized the impact that OA has had on their industry. They argue that OA models make it very difficult for publishers to cover even basic operating costs, much less to make a profit. It is estimated that an average research article costs $3500-$4000 to produce, and publishers have traditionally used subscription fees to cover these costs. Publishers are increasingly exploring new OA business models, but many continue to pursue hybrid approaches that maintain some non-open components. Similar arguments have been leveled at Open Data – data collection, cleaning, and dissemination can all be costly processes. Making datasets open can create a disincentive for companies to do this work.
These are all reasons why openness should not be pursued dogmatically, but rather extended carefully with full consideration of broader societal conditions. In this way we can achieve what The Royal Society (2012) describes as qualified openness, in order to capitalize on the benefits of openness while still safeguarding against situations “where research could in principle be used to threaten security, public safety or health.” (11) In the next section we explore Worldreader’s experiences pursuing qualified openness.
Worldreader’s approach to openness offers a nice illustration of the importance of approaching issues of openness carefully and pragmatically. In theory Worldreader likes the idea of open data and access, for many of the reasons discussed in the last section. This is exactly why they have used the tagline ‘Books for All’ to describe their mission!
However, their work is often affected by broader economic and political factors that can make open access problematic. Here we’ll highlight two sets of dynamics that lead them to make strategic compromises when it comes to openness. First, Worldreader’s business model is reliant upon complex relationships with book publishers and authors, all of whom have their own perspectives on openness. This dynamic clearly has a direct impact on the availability of books within the Worldreader system – without the cooperation of publishers, in particular, they would not be able to offer anything for readers. In order to include a book in their mobile application, Worldreader signs agreements for term licenses with publishers for mobile. Publishers have the legal right to sign these agreements based upon their own publishing agreements with their authors. However, there have been a few cases where the authors lacked an understanding of how these licenses are structured, and felt they were not being paid appropriately for their book’s inclusion within Worldreader’s app. Worldreader always directs the authors back to their publishers, to discuss the original agreement and clear up any issues directly. However, they are always happy to comply with takedown requests if it becomes necessary, or if there are discrepancies between the original publishing agreement and Worldreader’s agreement with the publishers. Their overriding concern is to maintain the long term relationship with the publishers, since this guarantees the most long term access to books for their users.
Worldreader’s uniquely structured publishing model also impacts this project’s research process. Worldreader creates unique contract terms for each of its publishers and is dedicated to supporting local authors and publishers in the geographies it serves. As a non-profit, they are able to do this by leveraging donated books and Creative Commons materials from international publishers.1 However, each contract varies and are very specifically focused on providing access to quality books, not open data. Out of respect for its publishers and often contractual obligation, Worldreader refrains from sharing information on reader engagement with specific titles without the publisher or author’s consent. For this project, that means that we need to be very careful, for example, about producing disaggregated analyses of particular reading trends. Instead of producing detailed analyses of the popularity of specific books, therefore, we might focus more on genres or book categories. While this makes our research data a little less open, it ensures that our research process does not endanger Worldreader’s relationship with its publishers – and, therefore, that it does not endanger long term access to books.
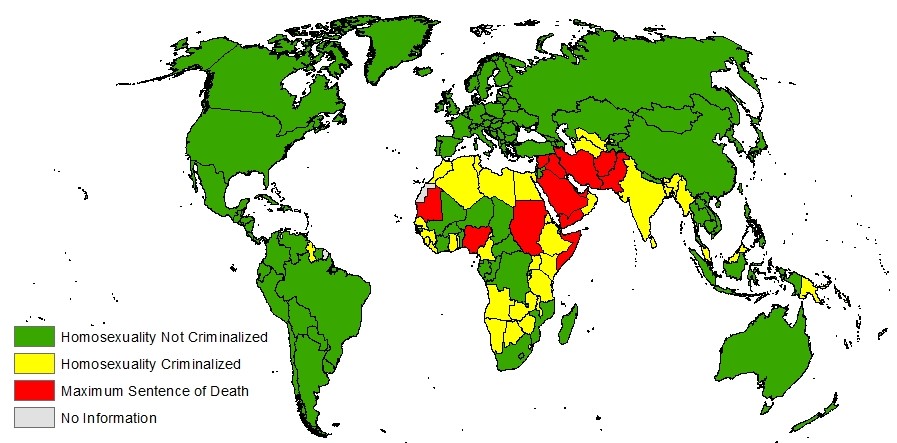
Second, Worldreader has to be careful about how its services interact with local culture and laws. The organization works primarily in countries where freedom of speech is not protected, and where there may be specific restrictions around books that they provide and that people choose to read. If Worldreader made all books available in all places, it could put their readers in danger – both legally and physically. In Nigeria, for example, it is best to avoid publishing material on homosexuality, since it is banned in the country – with punishment ranging from years in prison to death. Worldreader therefore does their best to curate their collection to reflect local desires. Generally, they try to achieve a good mix of books in their digital libraries for each country, with a heavy amount of locally-produced content, some open access books, and some classics from Western publishers. They do their best not to let their own biases shape what is accessible, but instead look at controversial content on a case-by-case basis. To make decisions on controversial content, they rely heavily on local guidance from their teams at regional hubs.
The data represented in this map are based on "State-Sponsored Homophobia: A World Survey of Sexual Orientation Laws: Criminalisation, Protection and Recognition," a 2017 ILGA report by Aengus Carroll and Lucas Mendos. Green represents countries that do not currently criminalize homosexuality, yellow represents countries that criminalize homosexuality in some fashion, and red represents countries that criminalize homosexualty and may, in some instances, penalize homosexuality with a maximum sentence of death. In some of those countries, death is a maximum legal sentence but has not been implemented.
They’ve learned a lot through this curation process. In some instances, some decisions on what content to include have been surprising. For example, some of their Ghana and Kenya team members and partners grew up with British storybooks published around the 1930s. These often espoused racist, colonial, and patriarchal views, which some felt uncomfortable including in the digital library for fear of extending negative representations of Africa. However, the local partners often expressed love and nostalgia for these books, and Worldreader eventually chose to pursue an opportunity to include the book in their collection. The process also highlights how Africa is not a cultural monolith – content that is controversial in one place can be unremarkable or even lauded in other locations. For example, a book on children’s sexuality from South Africa, called My First Time, caused a stir amongst some of Worldreader’s partners in Kenya. This was because the book contains frank and open discussions of sex, rape, and masturbation. In contrast, this same book was recently chosen for inclusion in collections in Zambia and Tanzania, with no resulting complaints. This demonstrates the importance of geography in shaping the impact of different types of openness.
These dynamics can, once again, be quite important to the research process. In countries where reading material on certain topics might be illegal, it becomes particularly important that our research not highlight potentially-controversial reading habits. The knowledge that certain demographics, and particularly already-oppressed minorities, are consuming controversial content can give authorities justification for arrests. It can also lead to other forms of persecution, such as mob justice or gender-based violence. We are therefore very careful to vet our analysis questions and outcomes with Worldreader, and particularly with their local experts, to minimize any risk of endangering Worldreader users.
Interestingly, despite all of these ethical issues related to this research, the project does not fall under the domain of the university’s Human Subjects Division (HSD). The UW HSB, which manages the university’s four Institutional Review Boards (IRBs), is designed to protect the safety and rights of research participants, to ensure institutional compliance with federal, state, and university policies, and to provide guidance to researchers on ethical issues. This is therefore the university body that would traditionally be most concerned with some of the ethical considerations discussed above. Because none of the data allow us to identify specific individuals, though, the HSD did not consider this to be human subjects research – and, therefore, not within their purview. This highlights some of the gaps between institutional ethics, as traditionally conceived, and some of the new ethical dilemmas that researchers are beginning to face in an age of big data projects and open, digital data. In our efforts to think through these ethical issues, Worldreader and TASCHA have set up a process for determining whether there is any risk to making particular forms of research open to the public. This ensures that our desire to open the research process and data does not negatively impact Worldreader’s partners, publishers, or readers. Our hope is that this allows the project to take advantage of all of the advantages of open data and access, while minimizing any of the potential drawbacks.
For more on Worldreader’s content licensing models see: http://bot.worldreader.org/licensing_models/ ↩
