Introduction to the Data Lifecycle - Analyzing and Sharing Data
3 hours
Download this module or visit our downloads page for more options
Student Objectives
- Understand basic concepts of data lifecycle - including the collection, analysis, and sharing of data for decision-making
- Understand key parts of the data analysis process, such as methods, cleaning data, coding data, and visualizing data
- Learn data visualization best practices
- Learn how to question your data and its integrity
- Understand how coding data can improve your analysis
- Learn different ways to share data
- Learn how to share data with metadata
- Be able to identify different open-sourced resources for data analysis
Materials
- Projector
- Computer
- Blackboard/whiteboard (ideally)
- Paper
- Pencils
- Printout of images used
- Activity packet 4.1
- Activity packet 4.2
- Student handbook
- Instructor Powerpoint slides
- Myanmar election data
- Sample data and metadata from aiddata.org
- As needed, online access or pre-selected printouts from http://paldhous.github.io/ucb/2016/dataviz/week2.html (To support the section “Best practices: Data visualization”)
-
Review
10 minutesWelcome the participants back. Review the following concepts. As before, have the participants give their own definitions before providing definitions for the following:
- Data life cycle
- Data collection
- Data analysis
- Data sharing
- Metadata
- Primary data
- Secondary data
- Methods of data collection
-
Activity 4.1: Questioning Your Data
25 minutesAdapted from: https://www.databasic.io/en/wtfcsv/wtfcsv-activity-guide.pdf
Objectives:
- Apply data analysis to a simplified dataset
- Learn how to ask a dataset questions based on its content
- Understand the importance of inspecting data for data reliability
- Think critically about how to supplement your data with other data sources if necessary
Materials Needed:
- Paper
- Pencils
- UFO dataset or other pre-selected dataset
- Projector
- Computer
Introduction: (Use the following information to introduce and explain the activity to the class)
This activity focuses on data reliability, question asking, and combining different data sources. Introduce the dataset to the class by projecting it on the screen and go over its contents together. What information is in the data set? What could be part of its metadata?
Then, pass out copies of the dataset and put the participants into groups of 2-3. Have the participants inspect the dataset and answer the following questions on their pieces of paper:
- What is the most interesting question you want to ask the dataset you are looking at?
- Do you need any other datasets to answer this question?
- How could you get the other data you need to answer this question?
Afterwards, provide a space for discussion and debrief surround the activity. Questions include:
- Are all the answers to your questions contained in the dataset?
- Where are the data from? If the sources of the data aren’t revealed, you should be skeptical.
- Do you see places where values are missing? Missing values are one way data can be “messy.” If the class is unfamiliar with the term “messy data”, take the time to define it.
- The data that were given to the class are aggregated summary data, but sometimes you can ask interesting questions about just one row in a dataset, or look for an “outlier”. Are there any “outliers” in the dataset? If the class Is unfamiliar with “outliers”, provide a definition for them.
-
Introduction to Key Concepts
15 minutesReintroduce the following image to the participants by passing it around or projecting it on the screen.
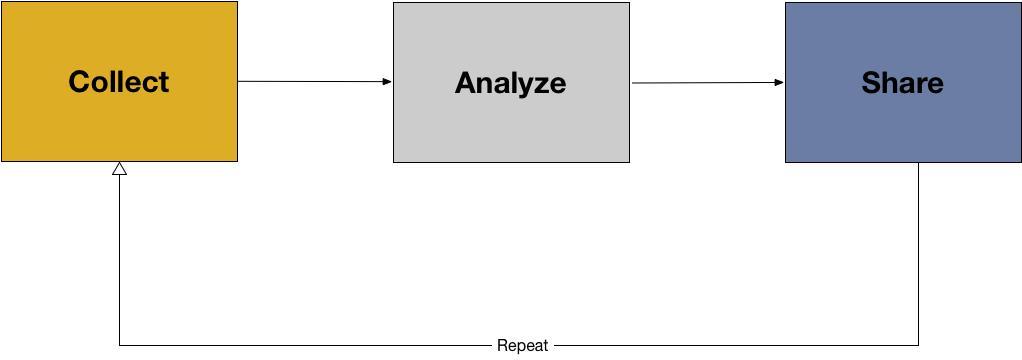
After collecting your data (Module 3), you unfortunately don’t have a brilliant flash of insight and understand how to solve the problem or answer your original question. In order to make meaning out of your data, you need to analyze your data, which is the next step in the data lifecycle after data collection.
Remind the class of the following definition for data analysis:
- Data analysis: data analysis is the process of inspecting, cleaning, transforming, and visualizing data with the goal of discovering its useful information, suggesting conclusions, and supporting decision-making. (Wikipedia)
The following are steps to follow in beginning any data analysis.
- Choosing method for analysis.
- This can be thought of as making meaning of the data, or how you will use the data to answer your question or solve your problem.
- We want to choose a method that helps us answer our question or our overall goal.
- For example, what if we want to know, which parties are most represented in state and region parliaments? To answer this we need election results data (including location information), and we will probably want to produce this on a map.
- Preparing data for analysis
- The next step is to prepare your data for analysis. Often, “raw data” straight from surveys, sensor data, or voter data can be “messy”, meaning it is not ready for analysis. To fix this, you often need to “clean” your data. Ask the participants what they think data cleaning might be. Then, provide the following definition:
- Data Cleaning means making sure that data are ready for analysis.
- Data cleaning depends on data type, and the method of analysis. In general, we should consider whether or not they are ready for analysis (e.g. are the values standard?). We can do an initial check on the data by picking some random values, and comparing them. We can also begin to “sort” the data by looking for minimum and maximum values, lists of values. If possible, use a dataset to demonstrate how to sort your data in excel or Google sheets
- Data Normalization
- After cleaning, the next step is data normalization, which means making all values consistent.
- This includes ‘0’ vs ‘NA’, using similar scales, using similar decimal points, dates, words, etc. For location data, we also want to initially make sure that all of our data are within the right map and all locations are uniformly named.
-
Understanding How to Make Meaning Out of Your Data – Descriptive Statistics
20 minutesNow that the data have been prepared, cleaned, and normalized, the next steps in data analysis are to make meaning out of our data by applying the method of analysis that has already been chosen in order to reach a conclusion. In many ways this is finding and accepting (or rejecting) an answer to our question.
We will cover three ways of making meaning with data in this workshop:
- Descriptive Statistics
- Coding qualitative data
- Visualization
First, we’ll begin with descriptive statistics. Ask the class if they have heard of descriptive statistics, or ask if they can think of a definition for descriptive statistics. Then, provide the class with the following definition:
- Descriptive statistics are statistics that quantitatively describe or summarize features of a dataset.
The following are descriptive statistics:
- Mean: the average or the norm.
- Use case: the mean (“average”) age of the students in the class is 13. (What could the student age data be to have a mean of 13? For example, everyone is age 13, or half the class is 12 and half the class is 14.)
- Median: the middle value
- Use case: the median price for a house is $50K (what could these data look like?)
- Mode: the most frequent value
- Use case: the mode of number of times individuals went to the library per week is 3
- Range: the highest and lowest values in a dataset
- Use case: the range of household income is USD $20K to $150K (What could these data look like? For example, almost everyone makes $20K but one person makes $150K.)
Explain to the participants that descriptive statistics can tell us what is typical in our dataset. For example, ask for volunteers to give their favorite numbers. Write the numbers on the board, if possible, and then walk the participants through finding the mean, median, and mode, and range of the numbers provided.
See Module4_Supplement for an example of how to calculate these statistics within Google Sheets
The next way to make meaning out of your data is to qualitatively code the data. Ask participants if they have coded data before. Also ask participants if they know what coding is and can provide a definition. Then, provide the following definition:
- Qualitative Coding: a process in which data, in both quantitative form (such as questionnaire results) or qualitative (such as interview transcripts) are categorized to make analysis easier.
There are several ways coding could be approached, for example:
- Iterative Coding (looking for common themes, and patterns in which to group the data)
- Card Sorting - show data columns to stakeholders, develop common understanding of data, and select appropriate data to communicate to public
If the above “coding” section is too advanced, there could be a description here that would give more advanced classes the opportunity to go in more depth about iterative coding and card sorting. If a class is less advanced or less familiar with this concept, then the above section can be skipped.
As an example, ask the participants a question such as for what they had for lunch today. Try to get as many answers as possible. Then, let the participants guide “coding” their answers into groups.
The final step in making meaning out of your data is visualization. Ask the participants why data visualization is important. How can it help in communicating and understanding your data? Underscore to the participants that visualization does not always have to be for an external audience. Often, visualizing your data will also help you, as the analyst, gain a greater understanding of the descriptive statistics of the data.
As an example, using the Myanmar election data set provided, make an in initial chart. Choose an independent (political party) variable for the x-axis and a dependent variable (number of coverage in state and region parliaments) for the y-axis. Does the data look correct? Are you surprised? How can the data be transformed for easier analysis?
-
Key Considerations
10 minutesIntroduce to the participants that there are a few things they should keep in mind throughout the data analysis process. These include:
There are often many questions that a dataset can answer, and often you will think of more to ask as you continue to analyze your data.
- Choose one initial question. Write it down. As new questions emerge, continue to write these down. You should prioritize answering your first question, but you may realize that it either is not the most important question or cannot be answered with the data you have. So be sure to incorporate some flexibility into your work.
Do I have enough data?
- This gets into notions of significance and representativeness of the data. For example, in looking at the age data that were collected in the descriptive statistics example, ask the students, were enough data collected? Do they provide an accurate enough picture of the class? What about of Myanmar as a whole? It isn’t always easy or straight-forward to determine if you have a representative sample. Sometimes you will have to make-do with simply reporting on your process. . It is always important to report the limitations of any analysis, which can be included in the way the results are reported are shared.
Do I trust the data that I have?
- Who collected these data? How? When were they collected? Is the sample size big enough?
- Always communicate how much data or what kind of data were used.
- Always communicate how you arrived at an answer, and what were the limitations of the data that were used.
The Lifecycle repeats itself:
- After doing some data analysis, it may be necessary to collect more data, or seek additional materials.
- This is a very normal part of doing data analysis – the lifecycle is a cycle for a reason – it is meant to be repeated a number of times before a project is over.
-
Activity 4.2: Making Meaning with your Data
35 minutesObjectives:
- Understand the importance of cleaning and coding data for analysis
- Learn how to identify when data need to be cleaned or coded
- Learn how to effectively code your data for analysis
Materials Needed:
If participants have computers:
- Laptops
- Excel
- Excel file for cleaning and coding
- Methods sheet for coding
If participants do not have computers:
- Printout of dataset worksheet
- Directions
- Codesheet
- Pens or pencils
Introduction: (Use the following information to introduce and explain the activity to the class)
Remind the class that in order for data to be used effectively for analysis and decision making, the data need to be properly cleaned and often re-coded. Cleaning data ensures that they are standardized and readable by the software. This often entails checking for standardization between different datasets, spelling errors, and capitalization. Coding data allows us to condense responses by different people into categories or patterns that are more beneficial to decision making analysis or for communicating to an intended audience. Coding is particularly useful when data-collection methods are open ended (e.g. demographic data questionnaires for occupation or education). Cleaning and coding are particularly important when visualizing data.
Example of the Importance of Cleaning
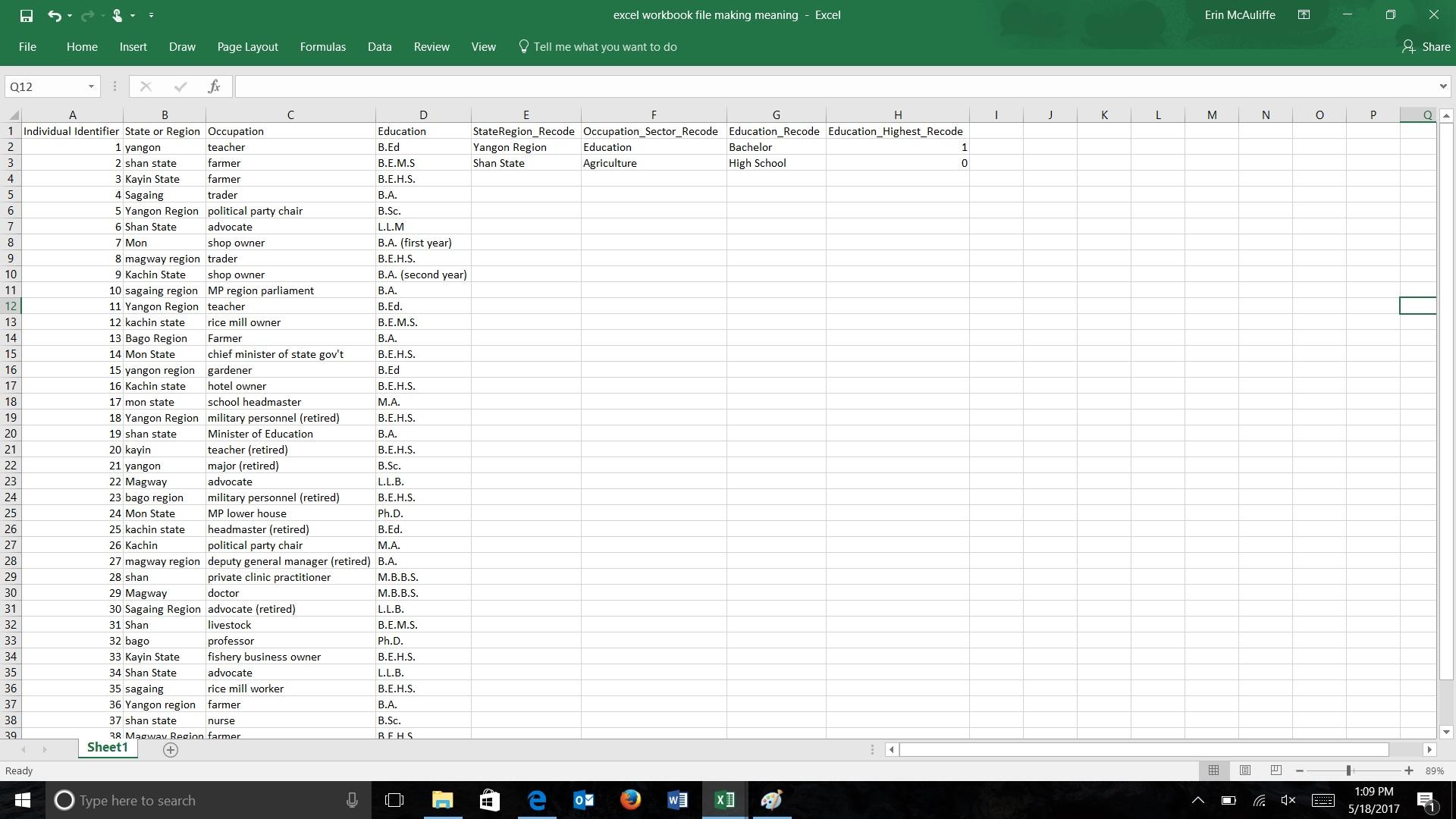
Pass around this image, or show it on the screen:
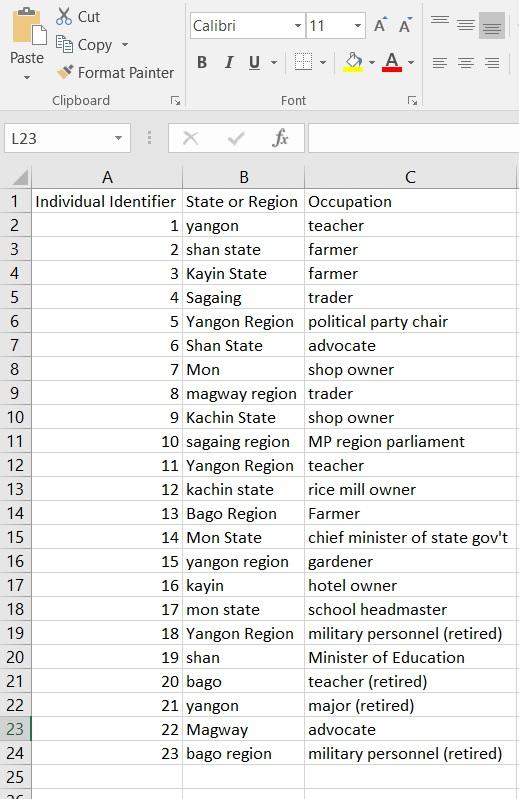
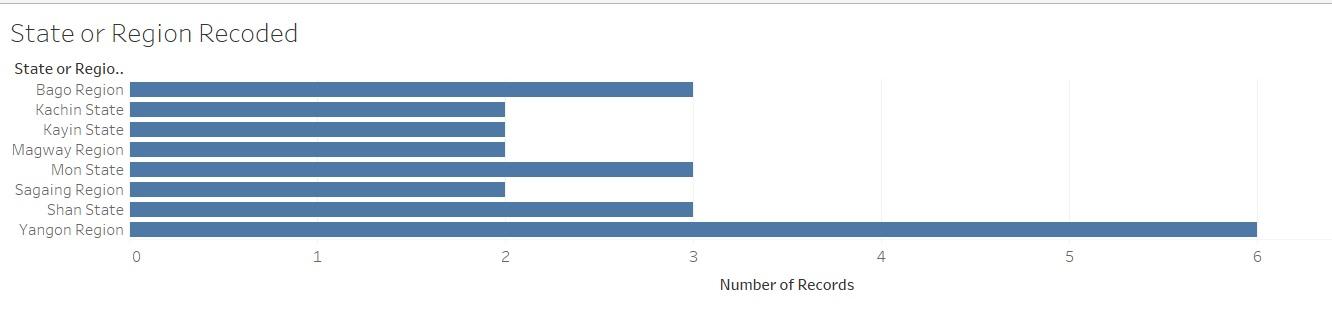
Ask the participants to look at the column labeled “State or Region” and ask them if they can identify any problems. Only allow up to one minute. If the participants do not answer or do not answer correctly, point out that some cells are labeled “yangon” or “Mon” while others are labeled “Yangon Region” or “Mon State.” Show them the same dataset, but visualized, to show what happens when you visualize data that are not cleaned:
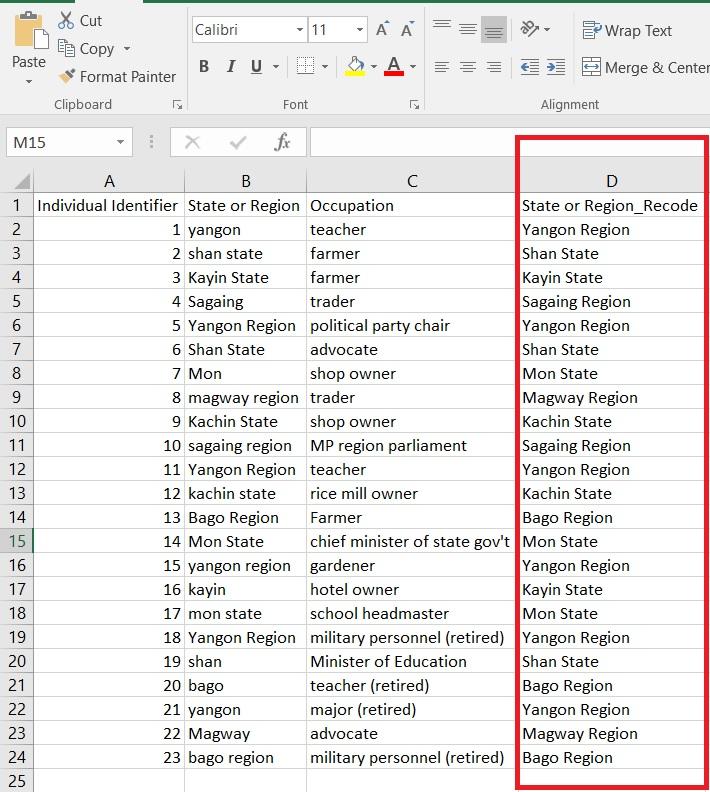
Allow the class 30 seconds to answer this question: Why is this visual problematic? They should answer that there are separate columns in the visual for the same state or region because the labels are different in the dataset.
Now show the class the dataset after it has been re-coded:
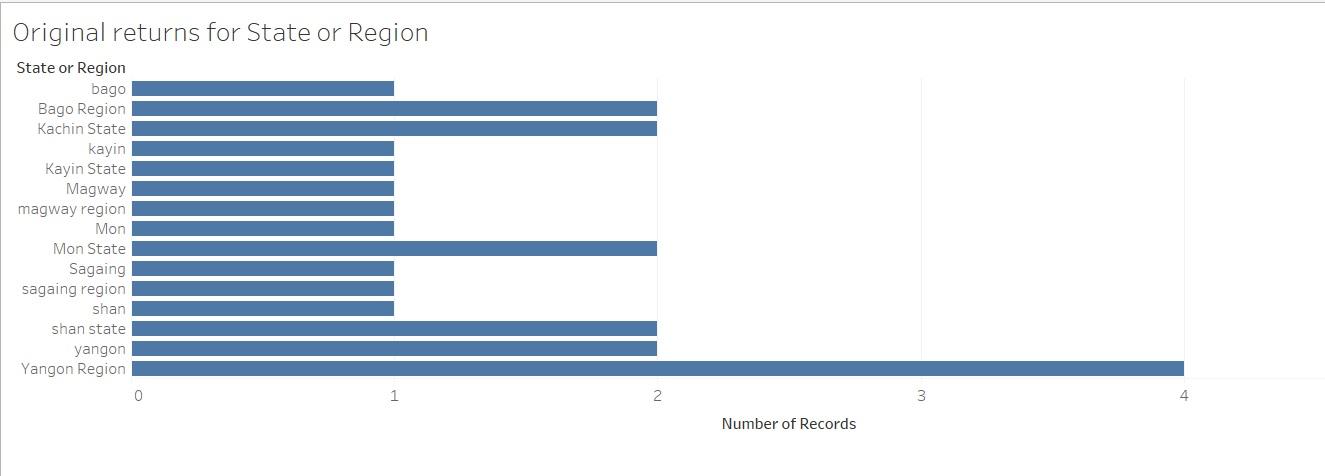
This dataset is taken from the working data files of the demographic data of elected MPs in Myanmar’s State and Region Parliaments. This was part of a project between the Enlightened Myanmar Research Foundation, the University of Washington, and Tableau Foundation in 2016. Explain to them that the new column is usually added at the end of the original table. The spelling and capitalization is the same for each row and the names for returns are standardized (for example, returns for Magway are re-coded as Magway Region and returns for shan are returned as Shan State).
Show them the same dataset visualized for the cleaned data:
Example of the Importance of Re-coding
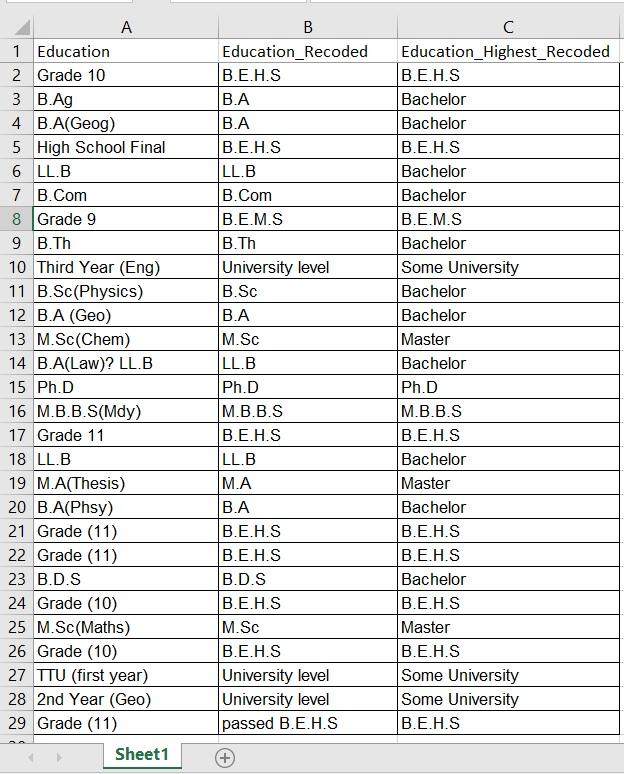
Pass around the image, or show it on the screen:
Ask the participants to look at Column A (Education). Inform them that these data were compiled from an open-ended response to “education” on a form for parliamentary candidates in Myanmar. Because individuals were not provided with a closed list of options to choose from, we can see that there are many different responses.
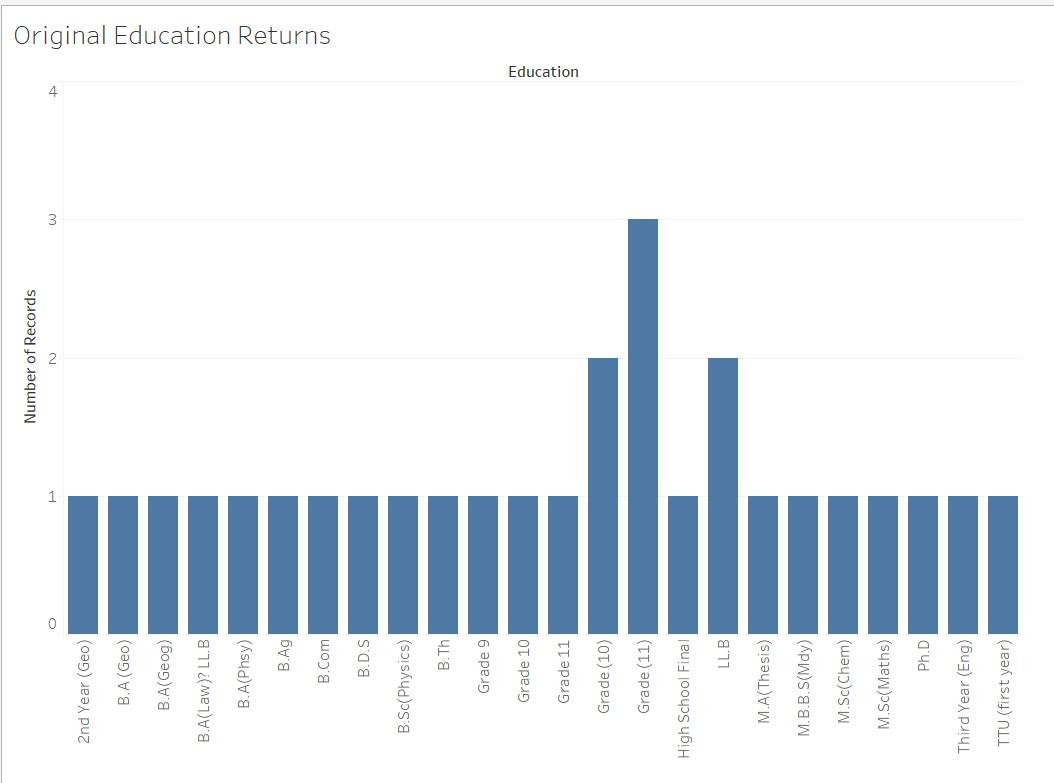
Show the participants this visual, which is the data in column A in visual format:
Explain to the participants that this does not easily tell us the educational attainment of the individuals. When there are many categories with few returns (in this case, one or two returns), the data should be re-coded
Return to the previous image of the dataset. Ask participants to look at Column C, which shows the data re-coded into the highest level of education completed. In re-coding the data, all degrees considered to be bachelor’s degrees were re-coded as “Bachelor.” Master’s degrees were re-coded as “Master.” Individuals who began university study but did not or have not yet completed a bachelor’s degree were re-coded into the category “Some University.” High School completion and middle school completion were re-coded into “B.E.H.S. and B.E.M.S. respectively. M.B.B.S., medical bachelor’s degree, remained as it was in the original dataset.
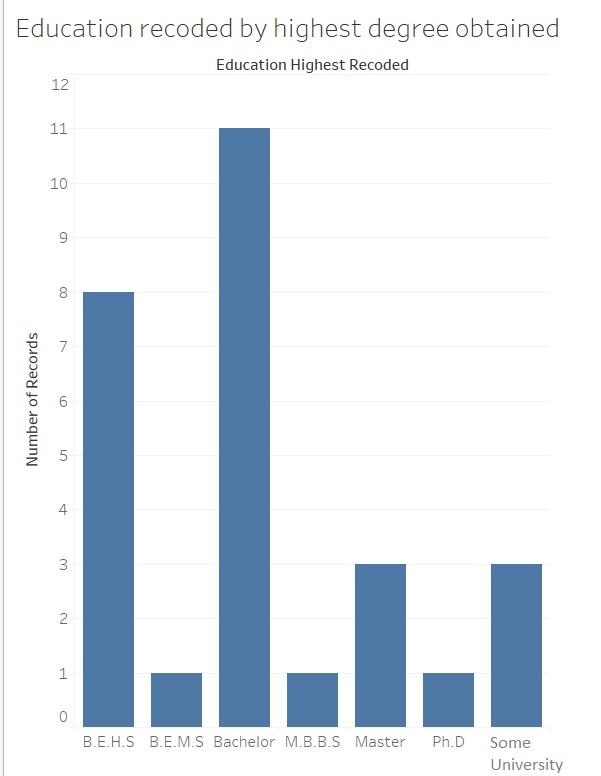
Now show the participants the recoded education data in visual format:
Ask them which visual provides more information about the educational attainment of the individuals? They should answer the second visual (re-coded data).
Now divide the participants into groups of 2-3. They will be given a dataset with data that need to be cleaned and coded. If participants are using computer, provide them with the excel file. If they are not using computers, provide them the paper copy of the excel file included in this activity. They will also be provided with a directions sheet and a codesheet that provides them with the categories and methods to be used to re-code the data for each indicator. If the class is more advanced, only provide them with the directions and make them create their own codesheet for re-coding the data. Working together, they should do the following:
- Clean the “State or Region” data so that they are standardized, spelled correctly, and capitalized the same.
- Re-code the “Occupation” data:
- Re-code the occupations by sector. The sectors that participants should use are provided on the codesheet. For example, farmers and individuals who work with livestock should be re-coded as “Agriculture.” Teachers and headmasters should be re-coded as “Education.”
- Re-code the “Education” data two different ways:
- First, by completed education (middle school, high school, some university, bachelor, master, Ph.D.). For example, B.A., B.Sc., L.L.B., and B.Ed. will all be classified as “bachelor”
- Second, by the highest education completed using four categories represented by numeric returns (0 = below bachelor; 1 = bachelor; 2 = above bachelor’s.) For example, B.E.M.S. and B.E.H.S. will be coded with a 0 because these education levels are below bachelor’s degrees. A Master’s degree and a Ph.D. will be coded with a 2, since they are degrees higher than a Bachelor’s degree.
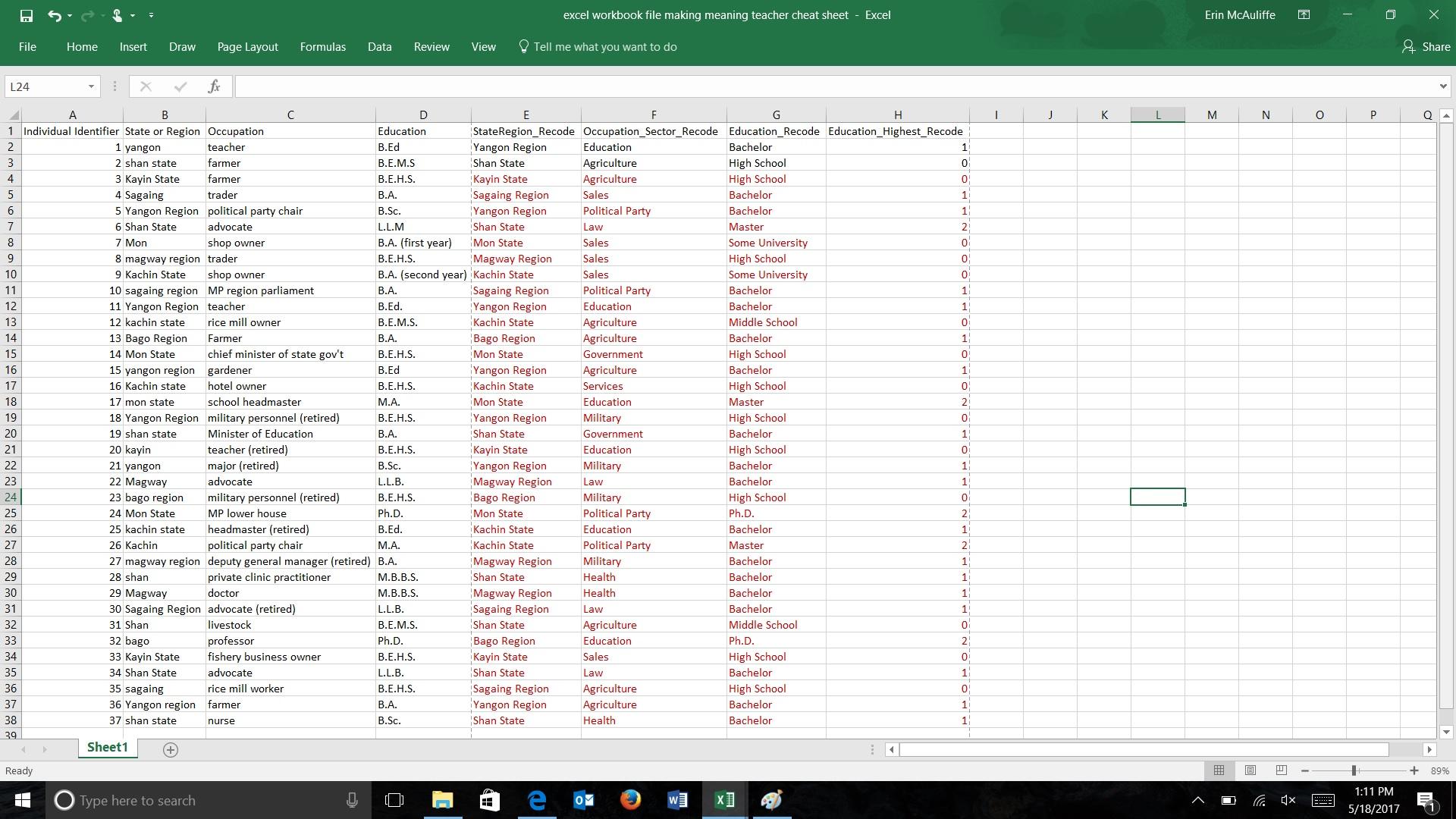
Walk around the room and provide participants with help as needed. Refer to the cheat sheet if needed.
At the end, provide each group with a cheat sheet, or put it up on the screen and allow them a maximum of 5 minutes to check their responses. Ask participants if they are confused or have any questions.
Last, ask the participants these questions:
- What was challenging?
- Why is cleaning and coding the data important?
Directions
- Please clean the data returns for “State or Region” (column B). You should provide the new cleaned data in Column E, “StateRegion_Re-code.”
- You should include the label “State” or “Region” following the name of the administrative territory. For example, Yangon Region or Shan State
- There should be a space between the territory name and the label State or Region and both should be capitalized. For example, Magway Region. Do not write magway region or MagwayRegion.
- See “Coding State and Region Data” for the comprehensive list of labels you should use for the re=coded column
- Please recode the Occupation data. The original occupation returns are provided in column C.
- Recode these by sector in Column F. A sector is a distinct part of society. In a state, key sectors are usually represented by a ministry or department. For a comprehensive list of sectors to use for re-coding and to decide which occupations should be recoded into the given sectors, refer to “Coding Occupation Sectors.”
- Please make sure that all re-coded returns (Column F) are capitalized and spelled correctly.
- Please recode the Education data. The original education data are provided in Column D.
- First, recode these data by education completed in Column G. The following categories should be used: Middle School, High School, Some University, Bachelor, Master, Ph.D. “Some University” refers to individuals who started a university degree but have not completed a bachelor’s degree. Please refer to “Coding Education Completed” to help you identify which returns should be re-coded under the new categories.
- Second, recode the data numerically to represent the highest educational level obtained in Column H. This return is intended to show who has not obtained a university degree (below bachelor), who has obtained a bachelor’s degree, and who has obtained a higher degree (master’s degree or Ph.D.). Please use the following numbers: 0 = below bachelor’s degree; 1 = bachelor’s degree; 2 = above bachelor’s degree. Please refer to “Numeric Coding for Highest Education Obtained” for a detailed explanation of which returns should be re-coded with each number.
Codesheet
Coding State and Region Data
Please use the following categories:
States Regions Kachin State Bago Region Kayin State Magway Region Mon State Sagaing Region Shan State Yangon Region
Coding Occupation Sectors
Please use the following sectors:
Sector Returns included Agriculture Farmer, Rice mill owner, Gardener, Livestock Education Teacher, Headmaster, Professor Government Minister Health Clinic practitioner, Doctor, Nurse Law Advocate Military Military personnel, Major, Deputy general manager Not Applicable Unknown, Dependent Political Party Political party chair, MP Sales Trader, Shop owner, Fishery business owner Services Hotel owner
Coding Education Completed
Please use the following categories to recode the education returns:
Education Recode Category Returns included B.E.M.S. B.E.M.S. B.E.H.S. B.E.H.S. Some University B.A. (first year), B.A. (second year) Bachelor B.A., B.Sc., B.Ed., L.L.B., M.B.B.S. Master M.A., M.Sc., L.L.M. Ph.D. Ph.D.
Numeric Coding for Highest Education Obtained
Please use the following numbers to represent the highest education level obtained:
Numeric Recode Highest Education Education Recode Categories included 0 B.E.M.S., B.E.H.S., Some University 1 Bachelor 2 Master, Ph.D.
Teacher Cheat Sheet:
Dismiss the class for a ten-minute break.
-
Providing Future Resources
25 minutesThe following section of this module provides participants with sample resources surrounding data analysis that they can return to in the future. If using a projector, take time to go to each website and click around, providing commentary with participants about the website’s purpose and how they can use the website in the future. If not, provide screenshots of each source that can be passed around to the participants as the instructor describes each data resource.
Sample Resources:
Making Meaning: Quantitative
Making Meaning: Qualitative
Making Meaning: Visualization
-
Introducing Key Concepts: File Types
15 minutesThe next part of the module explains how to share data. Remind participants about the importance of sharing data, as discussed in Module 2.
Knowledge sharing: an activity through which information, skills, expertise is exchanged between people, friends, and organizations. (Bulchandani, Linkedin, 2015)
Emphasize to the class that knowledge sharing helps create awareness among different organizations, helps facilitate faster solutions and improves response rates, can increase coordination, and can also provide ways for new ideas to be accepted and shared faster.
Engaging with other organizations allows them to learn from each other. You can share approaches, methods, tools, or instruments with each other. You should try to be as open as possible with sharing your data, your analysis, and your conclusions from that analysis.
To share your data, you should prepare the data into digital formats that can be easily shareable across organizations. Data should always be put into “open formats” or formats that can be accessed by most programs. These include:
- Text: .txt, doc
- Spreadsheet/Table: .csv or .tsv (comma/tab delimited), .xls
- Image: JPEG, PNG
- Audio: Mp3
- Video: MP4
Ask the participants if they have used any formats of these files before. If possible, open files on the computer and explore their extensions on a projector.
-
Understanding Key Concepts: Metadata, Publishing, and Communicating Data
15 minutesRemind participants about metadata. As before, ask if they can give their own definition of metadata before providing the following:
- Metadata: information that describes, explains, or gives context for other data. They are provided to make it easier to interpret, use, and manage data.
Metadata are important because they are used to add context to data. Metadata are the key for primary data to be used as secondary data. Examples of metadata types are:
- Descriptive Metadata - who created the data, when, where, what kind of data are these, and what topics / subjects do they contain?
- Administrative Metadata - how were the data produced, using what methods of data collection, and what instruments?
- Rights metadata - Who can use what resource, how , and under what conditions? (See how to choose a license)
Creating documentation
If wifi, a computer, and a projector are available, walk the participants through some of the replication data on aiddata.org. If not, take the time to print out some sample datasets along with their metadata for the class to pass around and analyze. Look at each dataset and its metadata: how does he metadata describe the data? How is it administrative? How does it describe rights?
Also take the time to explain the readme that accompanies a dataset. A readme file is a plain text file that describes the dataset or collection of files. Look through some example readme files as well. Then, provide a discussion for participants surrounding metadata and data within their own organizations. Sample discussion questions include: How can they create metadata so it is easily shareable? How can they use metadata to communicate the purpose of their research to other organizations? Why is metadata and its creation important?
Publishing Data
Publishing the documentation of your data is an important way to share your data with outside organizations and other governments. You should store your data in a data repository with a long-term preservation plan. This will ensure long-term access to your data and will offer back-up locations for it should the original files become corrupted.
Below are free services for data archiving:
-
Best practices: Data visualization
15 minutesThis final section about data sharing is about communicating the data to appropriate audience.
Take the time to project the following chart, or pass the image around to participants.
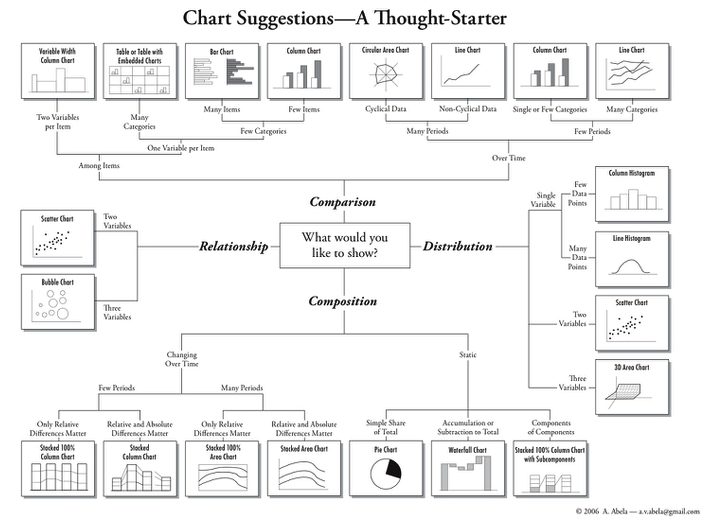
Walk the participants through the different types of charts, and how they should choose visualization types that will effectively communicate not only their data, but also the question they sought to answer with that data.
If access to wifi is available, access the following page for more information surrounding different types of visualizations. Of note are the sections starting from “simple comparisons” through ”composition”. http://paldhous.github.io/ucb/2016/dataviz/week2.html
Other best practices for data visualizations include:
- Label all axes.
- Create a legend that tells viewers what data are being used, and any limitations (e.g.sample size).
- Create a descriptive title.
- Provide a link to the original data, or contact information for the data producer.
Final Notes on Visualization:
- Visualization is often a useful exploratory tool but should not be the only exploratory tool as visualizations can sometimes be deceiving.
- In order for visualizations to be meaningful, the data used to create them must be accurate and useful.
- Any insights gained from visualization need to be backed up with proof of some kind – that might be statistics, or it might be some other source of evidence found in your data.
- The important thing to remember is that visualizations are valuable way to see data, but they are limited in the proof that they offer…Visualizations are often a way to see broad trends, not to pick out specific evidence or proof.
-
Debrief
5 minutesReview with the class that today they learned about the data lifecycle: collecting, analyzing, and sharing their data surrounding a problem or issue that they would like to solve.
State the tomorrow they will be putting Day 1 and Day 2 together, and will be working on a capstone project that will apply everything they have learned throughout the course. Take the time to answer any questions the participants may have, then dismiss the students for the day.